Back to main SpatiaLite-Tools Wiki page
Changes affecting the spatialite CLI frontend
A new dot macro already supported by the standard sqlite3 front end has been added starting since version 3.8.5:.shell CMD ARGS...... or .system CMD ARGS.....Both .shell and .system are exact synonyms: invoking the one or the other always produces identical effects. By invoking one of these new dot macros you are now free to executes any system command directly from the CLI; and this obviously extends to any SQL script being executed from the standard input.
$ spatialite ...... Enter ".help" for instructions SQLite version 3.8.5 2014-06-04 14:06:34 Enter ".help" for instructions Enter SQL statements terminated with a ";" spatialite> .shell ls -l *.sqlite -rw-r--r-- 1 sandro Administrators 27779072 Mar 5 18:44 beppe.sqlite -rw-r--r-- 1 sandro Administrators 427008 Jul 3 21:14 gpkg_test.sqlite -rw-r--r-- 1 sandro Administrators 276952064 Apr 28 19:00 grafo.sqlite spatialite>As you can see in this example, you simply have to specify the command name followed by any required argument immediately after declaring the .shell or .system macro.
new XML processing tools
Starting since version 4.2.0 three new tools have been added, and they are specifically intended to support XML processing via pure SQL:- spatialite_xml_load: this tool will parse any generic XML document of unlimited complexity, and will consequently create and populate a DB-file faithfully translating the XML tree into many relationally joined DBMS tables.
The whole translation is performed in such a way so to be sure that absolutely no information will be never lost or suppressed.
If two (or even more) XML files share exactly the same identical logical layout (i.e. they all support the same identical formal schema definition) this tool is capable to merge all them within the same DB-file.
There are no imposed size-limits: some huge GML files as big as many GBs have been successfully loaded by using this tool. - spatialite_xml_collapse: this tool is intended to simplify (by collapsing any not strictly required ramification) any DB-file created by spatialite_xml_load.
Collapsing a DB-file is a final irreversible operation. - spatialite_xml_print: this tool is intended to export a single XML
file corresponding to the current DB-file content.
It's useful i.e. when you've some way modified the original contents by performing some SQL operation.
when and why using the XML tools could be a brilliant idea
Just few general order considerations:- if you simply are an ordinary end-user (i.e. a people mainly interested in consuming already available data coming from external trusted sources) you'll probably judge the whole XML/SQL stuff boring, cumbersome and practically useless.
- if you are some kind of power-user (i.e. an highly skilled professional not worrying about performing complex data processing tasks) you'll probably find the XML/SQL tools some way interesting and may be sometimes useful.
- anyway the intended scope for the XML/SQL tools is to efficiently support complex (and possibly repetitive) processes related with data validation and acceptance tests. In other worlds: it's an highly specialized tool mainly intended for peoples involved in producing high-quality and robustly self-consistent datasets.
There are no practical limits except your own technical skills and creative imagination: you'll be now free to process, edit or validate your data in any possible way. And by wisely using SQL scripting techniques you could eventually nicely automatize many boring repetitive tasks.
If such a scenario sounds even vaguely interesting to you, giving a deeper glance at the new XML tools could be an interesting experience.
Mapping XML Entities into DBMS relational Tables: general order principles
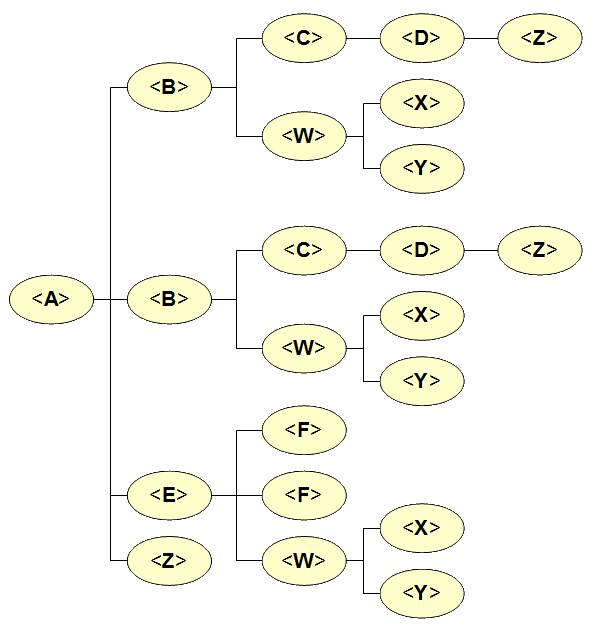
<W alpha="value1" beta="value2">
<X gamma="value3">value4</X>
<Y>value5</Y>
</W>
Accordingly to the XML format specifications:
|
|
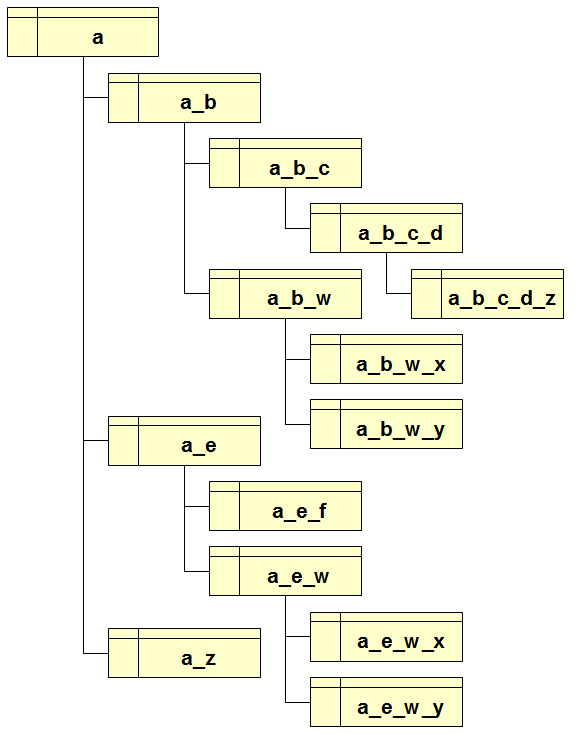
CREATE TABLE "a_b_c_d_z" ( node_id INTEGER PRIMARY KEY AUTOINCREMENT, parent_id INTEGER NOT NULL, node_value TEXT, CONSTRAINT "fk_a_b_c_d_z" FOREIGN KEY (parent_id) REFERENCES "a_b_c_d" (node_id) ON DELETE CASCADE);Each DBMS table will always support this basic layout:
CREATE TABLE "a_e_w" ( node_id INTEGER PRIMARY KEY AUTOINCREMENT, parent_id INTEGER NOT NULL, alpha TEXT, beta TEXT, node_value TEXT, CONSTRAINT "fk_a_e_w" FOREIGN KEY (parent_id) REFERENCES "a_e" (node_id) ON DELETE CASCADE);
|
|
Mapping XML Entities into DBMS relational Tables: fine-grained details
The above criteria allow to faithfully map any possible XML document into a DBMS relational schema. It's a nice and elegant design, it's rather simple and intuitive, and it can easily be extended so to automatically adapt to any possible data layout without imposing any constrained assumption.Anyway real-world XML documents can easily present very ramified and very deep tree structures, thus causing an impressive proliferation of the required DBMS tables. This is not a big issue by itself: any DBMS is surely capable to store many hundredths tables.
So the first practical problem we have to preliminary resolve is the one to assign appropriate (and possibly intuitive) names to each DBMS tables.
- a first naive naming criterion could be the one to simply assign artificially generated names safely ensuring uniqueness: e.g. as in tbl001, tbl002 and so on.
The main defect in this method is in that this way we'll certainly finishing to fight against lots of obscure and meaningless names; not at all a comfortable situation. - a surely better approach is the one to compose each table name by directly using XML node names exactly as they are, and chaining all the ancestors names so to precisely represent the hierarchical position of each table.
spatialite_xml_load exactly adopts such a criterion as its base naming strategy. Anyway this could easily produce intolerably long names, as e.g. dbtopofeaturecollection_dbtopofeaturemembers_porzioneterritoriorestituito_geometria_multisurface_surfacemember_polygon_interior_linearring_poslist; any attempt to use such a long table name in some SQL query will then be desperately impractical. - happily enough, a smarter criterion leading to shorter names is available.
Explicitly referencing the whole chain of ancestors always starting from the root node isn't usually required, because in many cases just referencing two or three ancestors (e.g. father, grandfather and great-grandfather) will ensure uniqueness. spatialite_xml_load supports such an advanced option.
A second option allowing to significantly reduce the depth of the XML tree structured is the one to immediately collapse all GLM geometries:
- GML notations are usually very verbose and very ramified.
- thus immediately resolving any GML geometry eventually found when parsing the input XML document will surely reduce both complexity and depth of the DBMS layout. A further benefit comes from activating this option; this way you'll immediately get a genuine SpatiaLite geometry you can directly use in any following SQL query.
XML MetaCatalog
Any DB-file created by the spatialite_xml_load tool will contain these two tables intended to facilitate the correct interpretation of the DBMS layout:- xml_metacatalog_tables: this first table will contain a row for each single table created by spatialite_xml_load.
- the table_name column is the Primary Key
- the tree_level column shows the corresponding depth of this Node in the XML tree (the root node corresponds to level 0).
- the xml_tag_namespace and xml_tag_name exactly correspond to the XML node name (as e.g. in <ns:tag>).
- the parent_table_name exactly identifies the corresponding parent node (will be NULL for the root node).
- the gml_geometry_column will be usually set to NULL, and will contain a meaningful value only in the case of collapsed GML Geometries.
- the status column will tell if the table was eventually affected by any subsequent post-processing operation (typically: after executing the spatialite_xml_collapse tool).
- xml_metacatalog_columns: this second table will contain a row for each column in the above tables.
- the table_name and column_name columns are the Primary Key; table_name is a Foreign Key referencing xml_metacatalog_tables.
- the origin column will state the intended role for the column (e.g. a value directly imported from the XML file, DBMS internal identifiers, and son on).
- the destination column will state if the column was affected by any post-processing operation (after executing the spatialite_xml_collapse tool).
- the xml_reference will exactly correspond to the original XML syntactic role of the column (if any).
The XML MetaCatalog contains many useful informations, and allows to fully reconstruct the original structure of the input XML tree.
It's used e.g. by the spatialite_xml_print tool when exporting again an XML document from the DBMS.
Tutorials and practical examples
- how-to process some simple GML dataset.
- how-to process some complex GML-Topology dataset.
Back to main SpatiaLite-Tools Wiki page
|
Credits Development of SpatiaLite XML-Tools 4.2.0 has been funded by Tuscany Region - Territorial and Environmental Information System Regione Toscana - Settore Sistema Informativo Territoriale ed Ambientale. |