
Recipe #1:
Creating a well designed DB
Note: these pages are no longer maintainedNever the less, much of the information is still relevant.Beware, however, that some of the command syntax is from older versions, and thus may no longer work as expected. Also: external links, from external sources, inside these pages may no longer function. |
|
Recipe #1: |
| 2011 January 28 |
| Previous Slide | Table of Contents | Next Slide |
|
Normal Form Any well designed DB adheres to the relational paradigm, and implements the so-called Normal Form.Very simply explained in plain words:
 Accordingly to this, it's quite easy to identify several flaws in the original Shapefile's layout:
And this dataset is in the 4326 SRID (WGS84), whilst any ISTAT - Census 2001 dataset is in the 23032 SRID [ED50 UTM zone 32]; so for now will simply keep this dataset in a completely self-standing state. We'll see later how we can actually integrate this dataset with the other ones: after all, all them represent Italy, isn't ? For sure some geographic relationship must exist ... |
|
CREATE TABLE regions ( region_id INTEGER NOT NULL PRIMARY KEY, region_name TEXT NOT NULL); |
|
INSERT INTO regions (region_id, region_name) SELECT COD_REG, REGIONE FROM reg2001_s; |
|
CREATE TABLE counties ( county_id INTEGER NOT NULL PRIMARY KEY, county_name TEXT NOT NULL, car_plate_code TEXT NOT NULL, region_id INTEGER NOT NULL, CONSTRAINT fk_county_region FOREIGN KEY (region_id) REFERENCES regions (region_id)); |
|
INSERT INTO counties (county_id, county_name, car_plate_code, region_id) SELECT cod_pro, provincia, sigla, cod_reg FROM prov2001_s; |
|
CREATE INDEX idx_county_region ON counties (region_id); |
|
CREATE TABLE local_councils ( lc_id INTEGER NOT NULL PRIMARY KEY, lc_name TEXT NOT NULL, population INTEGER NOT NULL, county_id INTEGER NOT NULL, CONSTRAINT fk_lc_county FOREIGN KEY (county_id) REFERENCES counties (county_id)); |
|
CREATE INDEX idx_lc_county ON local_councils (county_id); |
|
SELECT AddGeometryColumn( 'local_councils', 'geometry', 23032, 'MULTIPOLYGON', 'XY'); |
|
INSERT INTO local_councils (lc_id, lc_name, population, county_id, geometry) SELECT PRO_COM, NOME_COM, POP2001, COD_PRO, Geometry FROM com2001_s; |
|
CREATE TABLE populated_places ( id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL); |
|
SELECT AddGeometryColumn( 'populated_places', 'geometry', 4326, 'POINT', 'XY'); |
|
INSERT INTO populated_places (id, name, geometry) SELECT NULL, COL002, MakePoint(COL006, COL005, 4326) FROM cities1000 WHERE COL009 = 'IT'; |
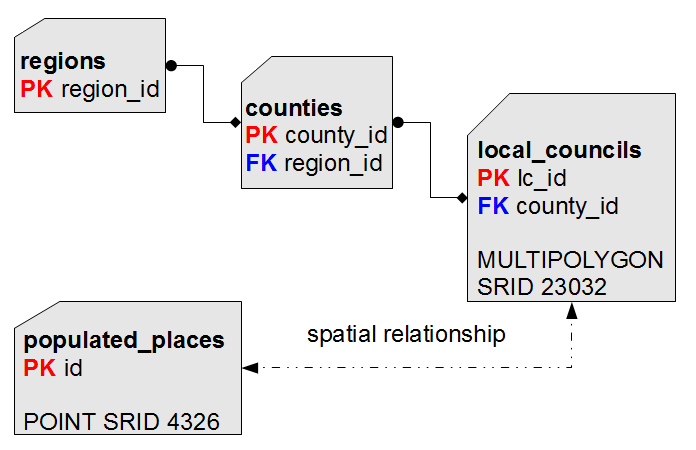
Just to recapitulate:
|
|
DROP TABLE com2001_s; DROP TABLE prov2001_s; DROP TABLE reg2001_s; DROP TABLE cities1000; |
| Previous Slide | Table of Contents | Next Slide |

| Author: Alessandro Furieri a.furieri@lqt.it |
| This work is licensed under the Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0) license. | |
 |
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. |