Quick Techical Introduction: in technical terms,
SpatiaLite is a
Spatial DBMS supporting international standards such as
SQL92 and
OGC-SFS.
Such a terminology may sound obscure and (
possibly) a bit overwhelming to you. Don't be afraid: very often, behind such technical jargon, a simple to understand concept exists:
- a DBMS [Database Management System] is software designed to store and retrieve arbitrary data in a efficient and generalized way..
Actually, it is nothing more than a storage place for lots of huge, highly structured, complex data.
-
SQL [Structured Query Language] is a standardized language supporting DBMS handling:
using SQL statements is
- how new storage areas are created and organized [CREATE]
- how new data is added [INSERT] to the storage areas
- how existing data is altered [UPDATE] in the storage areas
- how obsolete data is removed [DELETE] from the storage areas
- how data is searched for or retrieved (called query) [SELECT] from the storage areas
After learning how to use these 5 major commands, you will be able to perform most of the major tasks needed for a DBMS.
SQL statements enable you to use your data in a very flexible (and efficient) way.
-
OGC-SFS [Open Geospatial Consortium - Simple Feature Specification]
defines the extension of the basic DBMS / SQL capabilities, to support a special Geometry data-type, thus allowing the creation of a so-called Spatial DBMS
SpatiaLite is an extension of the very popular
SQLite, which is a lightweight, file-based, DBMS.
SQLite implements a standard SQL92 data engine (using the 5 major commands: CREATE, INSERT, UPDATE, DELETE, SELECT)
as does other Relational Database Management Systems such as PostgreSQL, MySql, Oracle and others
>
SpatiaLite implements the standard OGC-SFS core. as an extension of SQLite
in the same way as PostGIS extends PostgreSQL
Both, taken together, give you a complete
Spatial DBMS
since both SpatiaLite and PostGIS are extensions, they cannot work without the DBMS that they are based on.
Since both
SQLite and
PostgreSQL both implement the
standard SQL92 data engine
just as SpatiaLite and PostGIS implements the standard OGC-SFS core as extensions
What is the
difference between the them?
The simplest answer may be: 'All roads lead to Rome'
- one road, winding through a steep mountain path, may be fine for a single rider
- another road may be better for a carriage transporting a group of people with luggage
There are 2 major types of 'Relational Database Management Systems'
- one for single user / single application / standalone workstation
the category to which SQLite/SpatiaLite belongs to
- another for client-server architecture
the category to which PostgreSQL/PostGIS belongs to
So the major question should never be: is one '
better than the other?' , but '
how will the results be used?'.
In most cases the choice will be clear: either a
standalone or
client-server.
A third option is also possible:
both.
This is the case for Regione Toscana, not only a major funder of the Spatialite Project, but also a partial funder of PostGIS.
Based on its internal needs, both systems are used.
Since both systems are based on the same standards ( SQL92 and OGC-SFS), the results of both are the same.
The methods to achieve these results may (and do) differ, but the results are (and must be) the same.
A
SQLite/SpatiaLite solution offers the following:
- a file-based database (maybe, one containing several million entities)
- SQL engine, with Spatial-capabilities, is directly embedded within the solution
- cabability to convert, emulate and transfer data from/to PostGIS, FDO (GDAL), GeoPackage, Shapefiles and other Spatial-Formats
- reading and importing of other common formats such as TXT/CSV, DBF and Legacy-MS Excel
- cross-platform portable: not only are the database-files are easily transferable, but also the libraries to use them exist on most platforms
- stand-alone applications can be created, using the library's functionality, to create fine-tuned solutions
Conditions where a
SQLite/SpatiaLite solution may not be the best choice:
- for support for multiple concurrent access, a client-server DBMS, such as PostgreSQL/PostGIS, is required
Other useful references:
Note (2018):
This documentation was originaly written in 2011.
Not all of the images have yet been updated to the present day version and will be replaced at some point.
Notes will (hopefully) be written where you should no longer follow the instructions 'exactly'.
Download of the ISTAT (the Italian Census Bureau) dataset
The first dataset we'll use is the
Italian National Census 2011, kindly released by, and can be downloaded from:
ISTAT (the Italian Census Bureau).
Note: As of 2018-02-13, these Shapefiles have now been combinded into 1 archive.
Versione non generalizzata (più dettagliata) - WGS84 UTM32
(non generalized and more detailed; srid=32632)
Since ISTAT has published a lot of geographic open data during recent years, the URLs of individual datasets have been frequently subject to many sudden changes and rearrangements.
The presnt archive
used for this tutoral can downloaded from here:
http://www.istat.it/storage/cartografia/confini_amministrativi/archivio-confini/non_generalizzati/2011/Limiti_2011_WGS84.zip
or
[2018-09-06] Spatialite Server: Limiti_2011_WGS84.zip
Each category (Regions, Provinces and Communities) are in seperate directories:
- Censimento 2011 - Regioni (Regions):
Reg2011/Reg2011_WGS84 (.shp, .shx, .prj,dbf, .CPG)
- Censimento 2011 - Provincia (Provinces):
Prov2011/Prov2011_WGS84 (.shp, .shx, .prj,dbf, .CPG)
- Censimento 2011 - Comuni (Communities):
Com2011/Com2011_WGS84 (.shp, .shx, .prj,dbf, .CPG)
Each Shapefile will have a corresponding '.prj' file, which in this case contains the string 'WGS_1984_UTM_Zone_32N'
This Shapefile therefore uses SRID
32632 'WGS 84 / UTM zone 32N'
The used Charset Encoding is:
UTF-8 'UNICODE/Universal' (no longer
CP1252 'Windows Latin 1')
The Geometry-Type:
MULTIPOLYGON

8.092 Comuni (2011):
Ranging from large populated cities (Milano, Roma, Napoli) to very small villages.
The common denominator of each Comune being: its own coat-of-arms, Mayor and Local Police (traffic police).
Note: City, towns and villages.
|
110 Provinces:
Each province has its own Tribunal, Tax Office, Police HQ and other public offices.
Even more relevant in a catholic country, there is a Bishop for each Province.
Note: in many English speaking areas, this should be understood as a County,
in Canada often as a Region or Regional District.
|
20 Regioni:
Some of them are very big (Sicilia, Lombardia) and others very small (Umbria, Molise).
Five of them are semi-autonomous:
- Valle d'Aosta [Vallée d'Aoste] - French speakers
- Trentino/Alto Adige [Südtirol] - German speakers
- Friuli Venezia Giulia - speaking a Latin language different from standard italian and also with many slavic speakers
- Sicilia - home of Mount Etna, one of the world’s most active volcanoes
- Sardegna [Sardinia] - speaking a Latin language of their own, and with many catalan speakers in the north of the island
Note: in many English speaking areas, this should be understood as a State,
Canada and Ireland: Province and in the United Kingdom: Countries.
|
Download of the cities-1000 (GeoNames) dataset
The second required dataset is
GeoNames, a worldwide collection of Populated Places.
There are
several flavors of this dataset: we'll use
cities-1000 (
any populated place into the world with more than 1,000 people).
http://download.geonames.org/export/dump/cities1000.zip
or
[2018-09-06] Spatialite Server: cities1000.zip
Further datasets (not used in this tutoral) are:
The created columns 'COL006' and 'COL005' are latitude and longitude fields, thus SRID 4326 'WGS 84' must be used.
The used Charset Encoding is: UTF-8 'UNICODE/Universal
Based on the documentation found inside: http://download.geonames.org/export/dump/readme.txt
The main 'geoname' table has the following fields :
| Column-Number (created by VirtualText), column_name |
name |
description |
| COL001 / id_geoname |
geonameid |
integer id of record in geonames database |
| COL002 / name |
name |
name of geographical point (utf8) varchar(200) |
| COL003 / name_sort |
asciiname |
name of geographical point in plain ascii characters, varchar(200) |
| COL004 / name_alt |
alternatenames |
alternatenames, comma separated, ascii names automatically transliterated,
convenience attribute from alternatename table, varchar(10000) |
| COL005 / latitude |
latitude |
latitude in decimal degrees (wgs84) |
| COL006 / longitude |
longitude |
longitude in decimal degrees (wgs84) |
| COL007 / feature_class |
feature class |
see http://www.geonames.org/export/codes.html, char(1) |
| COL008 / feature_code |
feature code |
see http://www.geonames.org/export/codes.html, varchar(10) |
| COL009 / country_code |
country code |
ISO-3166 2-letter country code, 2 characters |
| COL010 / country_code_alt |
cc2 |
alternate country codes, comma separated, ISO-3166 2-letter country code, 200 characters |
| COL011 / admin1_code |
admin1 code |
fipscode (subject to change to iso code), see exceptions below, see file admin1Codes.txt for display names of this code; varchar(20) |
| COL012 / admin2_code |
admin2 code |
code for the second administrative division, a county in the US, see file admin2Codes.txt; varchar(80) |
| COL013 / admin3_code |
admin3 code |
code for third level administrative division, varchar(20) |
| COL014 / admin4_code |
admin4 code |
code for fourth level administrative division, varchar(20) |
| COL015 / population |
population |
bigint (8 byte int) |
| COL016 / elevation |
elevation |
source meters, integer. Use double to support mm |
| COL017 / dem_type |
dem |
digital elevation model, srtm3 or gtopo30, average elevation of 3''x3'' (ca 90mx90m) or 30''x30'' (ca 900mx900m)
area in meters, integer. srtm processed by cgiar/ciat. |
| COL018 / timezone_id |
timezone |
the iana timezone id (see file timeZone.txt) varchar(40) |
| COL019 / modification_date |
modification date |
date of last modification in yyyy-MM-dd format |
Download of the Railways vs Communities (rearranged work based on OSM) dataset
For the Railways vs Communities sample,a further dataset is needed.
This dataset represents a slightly rearranged work based on OSM and was originaly created for 'Cookbook 3.0' in 2011.
It is used to identify any Local Council that is being crossed by a railway line:
[2018-09-06] Spatialite Server: railways.zip
The Charset UTF-8 'UNICODE/Universal' can be used, since no special characters are being used in the 2 records.
This Shapefile uses: SRID 23032, 'ED50 UTM zone 32'
The Geometry-Type: MULTILINESTRING
Warning:
Since the other datasources use: SRID 32632 'WGS 84 / UTM zone 32N', some form of
- SELECT ST_Transform(geometry,32632)
must be used when interacting with this dataset.
Use the Load Shapefile function to create a railways table.
|
with spatialite_gui
After starting spatialite_gui, your first SpatiaLite working session, where no DB is currently connected.
The first step is to create / connect a new DB file:
- simply press the VirtualShape button of the tool bar
- a platform standard file open dialog will soon appear
- For the purpose of this tutorial, please name this DB as 2011.Italy.db
Once the creation of the DB has been completed:
- several Spatial Administration tables (aka metatables) can be seen
- these tables should, for now, be ignored
You can now load the first dataset:
- press the Virtual Shapefile button on the toolbar
- select the com2011_s. file.
A 'Creating Virtual Shapefile' dialog box will appear, where 'Path' is filled with the selected file:
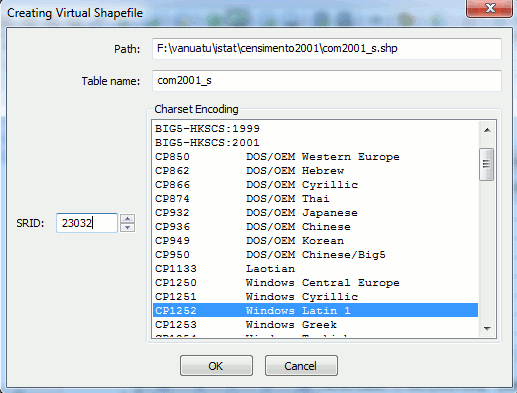
There are 3 pieces of information that must be supplied:
-
table-name: com2011_s is the name we will use for this tutorial
Select this name with care, for it will be often used
-
SRID: 32632 which is 'WGS 84 / UTM zone 32N'
Tip: looking inside the '.prj' file will help find out which EPSG number (SRID) to use
In this case you will see 'PROJCS["WGS_1984_UTM_Zone_32N"'
A Google search will result looking like this 'EPSG:32632'
-
Charset Encoding: UTF-8 which is: 'UNICODE/Universal'
Tip: older Shapefiles used CP1252 'Windows Latin 1')
newer Shapefiles often use: UTF-8 'UNICODE/Universal'
An automatic determination of which charset is being used is not possible
After importing, check the results.
If known special characters can be seen correctly: then you got it right.
If gibberish shows up: you got it wrong
Once com2011_s. has been loaded, do the same for:
The 'isoleamm2011_s' and 'zonecont2011_s'
are not used for this tutorial
Your database will now look like this:
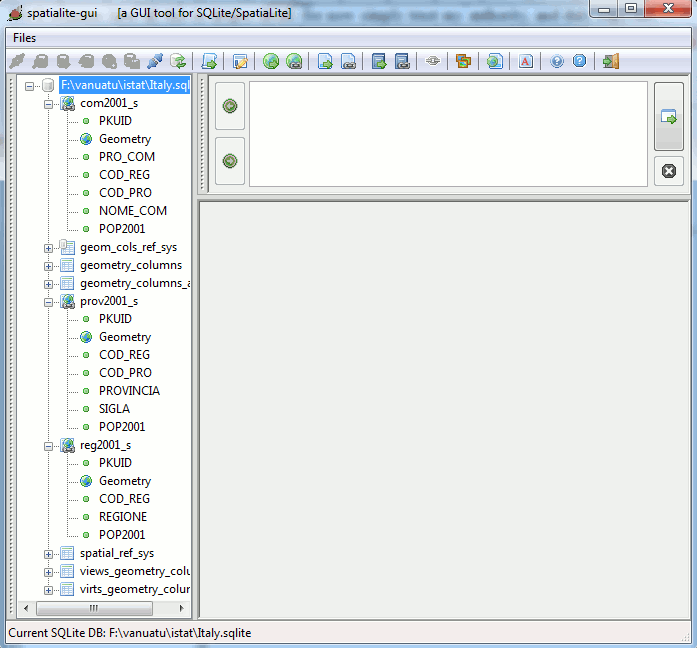
- The tree-view on the left side is used to list the tables (and columns within each table).
- The Text-Control (upper, right) will later be used to enter Sql-Commands (queries)
- The empty area (lower, right) will later show the results of the Sql-Commands (queries)
Now the final step to complete the initial DB setup:
We will use VirtualText to import the cities1000.txt. source:
- simply press the Virtual CSV/TXT button of the tool bar
You are now ready to complete the initial DB setup: press the Virtual CSV/TXT button on the toolbar,
and then select the cities1000.txt. file.
A 'Creating Virtual CSV/TXT' dialog box will appear, where 'Path' is filled with the selected file:
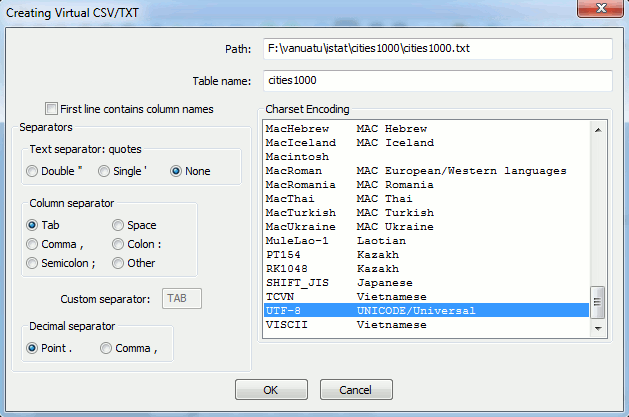
There are 6 pieces of information that must be supplied:
- table-name: cities1000 is the name we will use for this tutorial
- Charset Encoding: UTF-8 which is: 'UNICODE/Universal'
- First line contains column names: off
- Text separators: quotes: None
- Column separators: Tab
- Decimal separator: Points
These pieces of information should always be determined beforehand
Warning: Be careful when loading such text-files in an editor, when large, your system could start to crawl.
In Linux you can use the command head
head cities1000.txt > check_text.txt
In Windows, where 'Powershell' is installed, you can use the command type
type cities1000.txt -Head 10 > check_text.txt
both commands should copy the first 10 lines into the file named 'check_text.txt' and then be easly openend in any editor.
Note: I am not a Windows user, so I cannot confirm if the command really works
With that, you should now have 4 Tables, 3 of which contain geometries.
The next step is the creation of the TABLE cities1000 (press this link)
Creation of the Database 2011.Italy.db, with TABLEs com2011_s,prov2011_s and reg2011_s
with a sql-script
First import the data using the ImportSHP function and the VirtualText interface:
-- -- ---------------------------------- --
-- export SPATIALITE_SECURITY=relaxed
-- -- ---------------------------------- --
-- rm 2011.Italy.db ; spatialite 2011.Italy.db < import.shapes.sql
-- -- ---------------------------------- --
-- The main directory (Limiti_2011_WGS84) of the shape files and the cities1000.txt file
-- -> are expected to bein in the same directory as the script
-- --> adapt the path, when needed
-- -- ---------------------------------- --
SELECT ImportSHP
(
-- absolute or relative path leading to the Shapefile (omitting any .shp, .shx or .dbf suffix)
'Limiti_2011_WGS84/Com2011_WGS84/Com2011_WGS84',
-- name of the table to be created.
'com2011_s',
-- the character encoding adopted by the DBF member, as e.g. UTF-8 or CP1252
'UTF-8',
-- EPSG SRID value of shape file (has found in the .prj file)
32632,
-- name to assigned to the Geometry column
'Geometry',
-- name of a DBF column to be used in the Primary Key role
'pk_uid',
-- geometry_type of shap file
'MULTIPOLYGON',
-- casting to 2D or not; 0 by default
0,
-- compressed geometries or not
0,
-- immediately build a Spatial Index
1,
-- interpreting DBF dates as plaintext or not
0
);
-- -- ---------------------------------- --
-- if 'no such function: ImportSHP' shows up:
-- -> you forgot to set 'SPATIALITE_SECURITY=relaxed'
-- -- ---------------------------------- --
SELECT ImportSHP('Limiti_2011_WGS84/Prov2011_WGS84/Prov2011_WGS84','prov2011_s','UTF-8',32632,'Geometry','pk_uid','MULTIPOLYGON',0,0,1,0);
SELECT ImportSHP('Limiti_2011_WGS84/Reg2011_WGS84/Reg2011_WGS84','reg2011_s','UTF-8',32632,'Geometry','pk_uid','MULTIPOLYGON',0,0,1,0);
-- -- ---------------------------------- --
SELECT UpdateLayerStatistics('com2011_s');
SELECT UpdateLayerStatistics('prov2011_s');
SELECT UpdateLayerStatistics('reg2011_s');
-- -- ---------------------------------- --
-- These tables are not used in the tutorials: [isoleamm2011_s and zonecont2011_s]
-- -- ---------------------------------- --
SELECT ImportSHP('Limiti_2011_WGS84/AreeSpeciali2011_WGS84/Isole_amm_2011_WGS84','isoleamm2011_s','UTF-8',32632,'Geometry','pk_uid','MULTIPOLYGON',0,0,1,0);
SELECT ImportSHP('Limiti_2011_WGS84/AreeSpeciali2011_WGS84/Zone_cont_WGS84','zonecont2011_s','UTF-8',32632,'Geometry','pk_uid','MULTIPOLYGON',0,0,1,0);
-- -- ---------------------------------- --
SELECT UpdateLayerStatistics('isoleamm2011_s');
SELECT UpdateLayerStatistics('zonecont2011_s');
-- -- ---------------------------------- --
CREATE VIRTUAL TABLE virtual_cities1000 USING
VirtualText
(
-- absolute or relative path leading to the textfile
'cities1000.txt',
-- charset encoding used by the textfile
'UTF-8',
-- does the first line contains column names [0=no, 1=yes]
0,
-- the decimal separator [POINT or COMMA]
POINT,
-- the text separator [NONE, SINGLEQUOTE or DOUBLEQUOTE]
NONE,
-- the field separator [TAB, ',', ':' or other character]
TAB
);
Creation of the TABLE
cities1000
After the VirtualText source has been created (either through
spatialite_gui left, or through sql-command above)
the next step will be to CREATE and fill (using INSERT) the final table
Based on 'geoname' table we will create the needed Sql-Commands that will:
- create usable column-names
- insures that the correct data-types are created
- order the data in a form that we prefer
First create a TABLE, using the SQLite and SpatiaLite syntax:
Notes:
The description tells you which data-type is being used, which must be translated to the SQLite syntax:
- 'varchar, char,characters': TEXT
- 'integer, int, bigint': INTEGER
- 'decimal degrees': DOUBLE
- 'date (yyyy-MM-dd format)': DATE
It also tells us that the text is UTF-8 and that the positions are in WSG84, which is EPSG:4326
Tips:
The original CREATE SQL command will be stored in the database.
I always create a well formatted (and thus readable) script with comments for each field.
so that at a later date, when one has forgotten the meaning of the field, one can look it up
This may be a bit wasteful, but nevertheless, in the long term, useful (and a matter of style).
CREATE TABLE IF NOT EXISTS cities1000
(
-- integer id as primary key
id_rowid INTEGER PRIMARY KEY AUTOINCREMENT,
-- integer id of record in geonames database
id_geoname INTEGER DEFAULT 0,
-- name of geographical point
name TEXT DEFAULT '',
-- name of geographical point in plain ascii characters (sortable)
name_sort TEXT DEFAULT '',
-- alternatenames, comma separated, ascii names automatically transliterated, convenience attribute from alternatename table
name_alt TEXT DEFAULT '',
-- latitude in decimal degrees (wgs84) [Y-Position]
latitude DOUBLE DEFAULT 0,
--longitude in decimal degrees (wgs84) [X-Position]
longitude DOUBLE DEFAULT 0,
-- feature class: see http://www.geonames.org/export/codes.html
feature_class TEXT DEFAULT '',
-- feature code: see http://www.geonames.org/export/codes.html
feature_code TEXT DEFAULT '',
-- country code: ISO-3166 2-letter country code
country_code TEXT DEFAULT '',
-- alternate country codes, comma separated, ISO-3166 2-letter country code,
country_codes_alt TEXT DEFAULT '',
-- fipscode (subject to change to iso code), see exceptions below, see file admin1Codes.txt for display names of this code
admin1_code TEXT DEFAULT '',
-- code for the second administrative division, a county in the US, see file admin2Codes.txt;
admin2_code TEXT DEFAULT '',
-- code for third level administrative division
admin3_code TEXT DEFAULT '',
-- code for fourth level administrative division
admin4_code TEXT DEFAULT '',
-- Project POINT '1000' meters due NORTH of start_point, return distance in wgs84 degrees for 1 Km
distance_degrees_km DOUBLE DEFAULT 0,
-- bigint (8 byte int)
population INTEGER DEFAULT 0,
-- elevation: source in (whole) meters, Convert to DOUBLE
elevation DOUBLE DEFAULT 0,
-- digital elevation model, srtm3 or gtopo30, average elevation of 3''x3'' (ca 90mx90m) or 30''x30'' (ca 900mx900m)
-- area in meters, integer. srtm processed by cgiar/ciat
dem_type INTEGER DEFAULT 0,
-- the iana timezone id (see file timeZone.txt)
timezone_id TEXT DEFAULT '',
-- date of last modification
modification_date DATE DEFAULT '0001-01-01'
);
Now we have to add an appropriate Geometry column to the Table we've just created.
SELECT AddGeometryColumn
(
-- table-name
'cities1000'
-- geometry column-name
'geom_wgs84'
-- srid of geometry
4326,
-- geometry-type
'POINT'
-- dimensions of geometry
'XY'
-- permit NULL values for geometry [0=yes; 1=no]
0
);
And finally we'll create a Spatial Index supporting the Geometry column we've just added. This is not always strictly required, but it's a good coding practice in many cases.
SELECT CreateSpatialIndex
(
-- table-name
'cities1000',
-- geometry column-name
'geom_wgs84'
)
For the SELECT command, we will be using a combination of:
Which will also show some of the powerful capabilities that SQL has to offer.
Goals:
The populating of the final TABLE will attempt to accomplish the following:
- insure that numeric data is stored as such (using 'CAST')
- values not set in the original source and stored in SQLite as NULL receive a default value
- creating a geometry from the latitude/longitude values
- sorting the TABLE based on the Country, Admin1 and Name values
The final result, should be, a cleaned up and valid SQLite/SpatiaLite Spatial-TABLE:
INSERT INTO cities1000
(id_geoname, name, name_sort, name_alt, latitude, longitude, feature_class, feature_code, country_code, country_codes_alt,
admin1_code, admin2_code, admin3_code, admin4_code, population, elevation, dem_type, timezone_id, modification_date, geom_wgs84)
SELECT
-- Total records NOT NULL: [128566]
COL001 AS id_geoname,
-- There is a CAST(COL002 AS TEXT) Function, but not needed since TEXT is the default.
COL002 AS name,
-- Set to empty, if there is no value [1]
CASE WHEN COL003 IS NULL THEN '' ELSE COL003 END AS name_sort,
-- Set to empty, if there is no value [22636]
CASE WHEN COL004 IS NULL THEN '' ELSE COL004 END AS name_alt,
-- Cast to DOUBLE to insure that the stored value is numeric
CAST(COL005 AS DOUBLE) AS latitude,
-- Cast to DOUBLE to insure that the stored value is numeric
CAST(COL006 AS DOUBLE) AS longitude,
COL007 AS feature_class,
COL008 AS feature_code,
COL009 AS country_code,
-- Set to empty, if there is no value [124289]
CASE WHEN COL010 IS NULL THEN '' ELSE COL010 END AS country_codes_alt,
-- Set to empty, if there is no value [11]
CASE WHEN COL011 IS NULL THEN '0' ELSE COL011 END AS admin1_code,
-- Set to empty, if there is no value [25563]
CASE WHEN COL012 IS NULL THEN '' ELSE COL012 END AS admin2_code,
-- Set to empty, if there is no value [65400]
CASE WHEN COL013 IS NULL THEN '' ELSE COL013 END AS admin3_code,
-- Set to empty, if there is no value [109768]
CASE WHEN COL014 IS NULL THEN '' ELSE COL014 END AS admin4_code,
-- Cast to INTEGER to insure that the stored value is numeric
CAST(COL015 AS INTEGER) AS population,
-- Set to 0, if there is no value [102267]. Cast to DOUBLE to insure that the stored value is numeric and could then support mm
CASE WHEN COL016 IS NULL THEN 0 ELSE CAST(COL016 AS DOUBLE) END AS elevation,
-- Set to empty, if there is no value [0]
COL017 AS dem_type,
-- Set to empty, if there is no value [0]
COL018 AS timezone_id,
-- There is no CAST(COL019 AS DATE) Function
COL019 AS modification_date,
-- create the original POINT as Wsg84 [you cannot use the 'AS longitude/latitude' names here!]
MakePoint(CAST(COL006 AS DOUBLE), CAST(COL005 AS DOUBLE), 4326) AS geom_wgs84
FROM virtual_cities1000
-- Sort by country, highest admin-level and name [using the 'AS name' ]
ORDER BY country_code,admin1_code, name;
Calulate, for each POINT, the distance in degress for 1000 meters: (for use with ST_Buffer):
UPDATE cities1000 SET distance_degrees_km =
(
--- Project POINT '1000' meters due NORTH of start_point, return distance in wgs84 degrees for 1 Km
SELECT ST_Distance(geom_wgs84,ST_Project(geom_wgs84,1000,0))
);
Last, but not least:
- update the metadata
- remove the (no longer needed) VirtualText table
- and a message telling us (possibly) something useful
-- -- ---------------------------------- --
-- Update the metadata for the database
-- -- ---------------------------------- --
SELECT UpdateLayerStatistics
(
-- table-name
'cities1000',
-- geometry column-name
'geom_wgs84'
);
-- -- ---------------------------------- --
-- DROP the VirtualText table, since it is no longer needed
-- -- ---------------------------------- --
DROP TABLE IF EXISTS virtual_cities1000 ;
-- -- ---------------------------------- --
SELECT 'Records imported into ''cities1000'': '||(SELECT count(id_geoname) FROM cities1000)||' --done--' AS message;
-- -- ---------------------------------- --
-- Records imported into 'cities1000': 128743 --done--
Now the search for everything we have missed can begin ....
Summa summarum:
Importing a CSV/TXT file seldom can be done automatically
You need to analyse and prepare the data properly. This is why a 2 step process is advised.
- Use VirtualText to temporary to view the data as it will be seen in a database
- create a SELECT statement to fill the final TABLE in the form you need.
This is the main reason why there is no ImportCSV function.
What's a Shapefile ?
Shapefile is a plain, unsophisticated GIS (geographic data) file format invented many years ago by ESRI:
although initially born in a proprietary environment, this file format has been later publicly disclosed and fully documented, so it's now really like an
open standard format.
It's rather obsolescent nowadays, but it's universally supported.
So it represents the
lingua franca every GIS application can surely understand: and not at all surprisingly, SHP is widely used for cross platform neutral data exchange.
The name itself is rather misleading: after all,
a Shapefile isn't a simple file.
At least three distinct files are required (identified by
.shp .shx .dbf suffixes):
If of these are missing (
misnamed / misplaced / malformed or whatsoever ), then the whole dataset is corrupted and become completely unusable.
Manditory files
- .shp : shape format; the feature geometry itself
- .shx : shape index format; a positional index of the feature geometry to allow seeking forwards and backwards quickly
- .dbf : attribute format; columnar attributes for each shape, in dBase IV format
Other files
-
.prj :projection format; the coordinate system and projection information, a plain text file describing the projection using well-known text format
When an
SRID is needed, looking inside the '
.prj' file will help find out which EPSG number (SRID) to use
In this case you will see something starting with:
- PROJCS : Projected Coordinate System
or
- GEOGCS : Geographic Coordinate System
which will be followed with text indicating the
name of the projected or geographic coordinate system.
A Google search for this
name will often show up in the result something starting with 'EPSG:':
- WGS_1984_UTM_Zone_32N 'EPSG:32632'
- DHDN_Soldner_Berlin 'EPSG:3068'
- ETRS_1989_UTM_Zone_33N 'EPSG:25833'
will, in most cases, a result will be returned, where the url adress contains:
spatialreference.org/ref/epsg/
This page will contain the needed
SRID value, which mostly also an
ESPG value.
Some useful further references:
What's a Virtual Shapefile (and Virtual Tables) ?
SpatiaLite supports a Virtual Shapefile driver: i.e. it has the capability to support SQL access (
read-only mode) for an external
Shapefile, with no need to load any data within the DB itself.
This is really useful during any preliminary database construction step (as in our case).
SQLite/SpatiaLite supports several other different Virtual drivers, such as the Virtual CSV/TXT, the Virtual DBF and so on ...
Be warned: Virtual Tables suffer from several limitations (
and are often much slower than using internal DB storage), so
they are not at all intended for any serious production task.
For a full description of this and other Virtual-Interfaces that emulate external Spatial-formats, visit the main Wiki-Pages:
Very simply stated:
- any computer really only a stupid machine built out of a messy bunch of silicon
- can add 1+1 with the result of 10
- when told to do so, can make more errors in a few seconds that you could during your lifetime
- absolutely unable to understand text, other that adding (if told to do so) the characters to each other
- a conversion table must exist for the computer to translate its straightforward '0' and '1's, to the, many different, messy, alphabets that it exists in the world
This
conversion table is known as as a
Charset Encoding.
The viewpoint of the computer is:
Be it as it may,
Charset Encoding.problems are caused by the historical development of text files.
So lets invest the time to collect the needed information to the understand the
cause of the problem.
The historical development of Text-Files
Basically, the original text files were a major source for
printers.
ASCII, which envolved during the years 1963, 1967 and 1986 and were used in first
Unix, the development of which started in 1969.
It was based on earlier teleprinter encoding systems, which was based on the English alphabet.
- 128 specified characters ; 95 printable and 33 non-printing control codes
- All uppercase come before lowercase letters; for example, "Z" precedes "a"
- Digits and many punctuation marks come before letters
- For sorting, uppercase letters were converted to lowercase before comparing ASCII values.
2 (non-printing) control codes can be used in text files
- CR - Carriage Return [0x0D (13 decimal)]
- LF - Line Feed or New Line [0x0A (10 decimal)]
For text files the following character was used for 'New Line':
- CR - Macintosh, (pre-OSX MacIntosh)
- LF -Unix/Linux and OSX MacIntosh
- CR+LF - CP/M, DOS and Windows
- LF+LF - (empty last line) POSIX definition of end of file
This is the cause of the
Small Confusion when transfering Text files between non-mainframe computers.
Mainframe computers mostly use the
EBCDIC character set, that has it own set of
code pages to make life miserable for anybody that needs to deal with it.
Around 1981, when the IBM-PC was introduced,
Extended ASCII, which contained 256 characters, became more common.
This was when the
Great Confusion started: the introduction of
code pages
- the first 128 characters remained unchanged
- the last 128 would be interpreted by the code page being used
Since the
code page number is never stored inside a text file (as source for
printers, that information would also be printed)
it is almost impossible to determine how any character, using a value > 127, is to be interpreted
Below is a list of 15 different code pages, using the
same character value of Hex(0xD8) Decimal(216).
Starting around 1989 the development
Unicode was started, with the goal of resoving these problems.
UTF-8 was
introduced in the Unix-Kernal in 1992, and is now used as default in many systems (since 2009 in WWW)
the first 128 characters are the same as ASCII
For each character a
unique value exists.
Below is a list of the 14 different, unique,
UTF-8 values, that corresponds to Hex(0xD8) Decimal(216), togeather with a specific
code page number:
Summa summarum:
When reading a ASCII-based text, and the character Hex(0xD8) is being read
the Code-Page used to create and display that character must be known to translate it to the Unicode value
If the
Code-Page 1256 (Arabic) has been given:
then Hex(0xD8) will be converted to the Unicode value of Hex(0x0637) and displayed as 'ط'
Anything else is just a
hocus-pocus that will not result in anything useful.
For this reason, you are advised to use
VirtualText to import the data and
check the results.
Since all text in SQLite is assumed to be stored as
Unicode, the way the data is shown in
spatialite_gui
after importing it with VirtualText will be the same as with any other application
The Sample Database (where the Shape-file was supplied was in
UTF-8) contains a table
reg2011_s", with is a list of Regions in Italy.
2 of these Regions contain special characters (an '
é' and '
ü'):
- Valle d'Aosta/Vallée d'Aoste
- Trentino-Alto Adige/Südtirol
which
are shown correctly.
If you had imported this Shape-file as CP_1252 (Windows Latin 1), then these Regions would have been listed as:
- Valle d'Aosta/Vallée d'Aoste
- Trentino-Alto Adige/Südtirol
which
are not shown correctly.
This is the only way to insure that the text data is imported correctly.
Some other, useful references:
Most Planets, such as Earth, are a
sphere ... not exactly, Earth has an
ellipsoidal shape (
slightly flattened at the poles) ...
oh no, that's absolutely wrong: Earth isn't a geometric regular shape, it actually is a
geoid
All the above assertions can be assumed to be true, but at different approximation levels.
Near the Equator differences between a sphere and an ellipsoid are rather slight and quite unnoticeable
but nearer to the Poles such differences becomes greater and most easily appreciable.
For all practical purposes differences between an ellipsoid and a geoid are very similar
but for long range aircraft navigation (or even worse, for satellite positioning),
these differences must be taken into consideration. to receive reliable results.
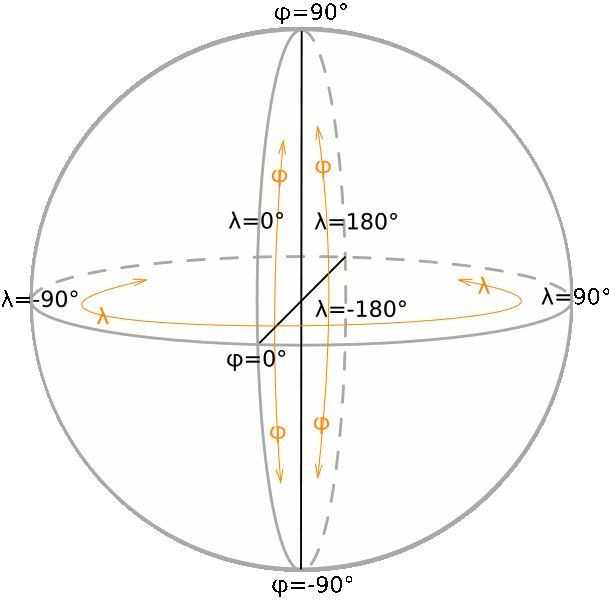
Independent of the real shape of the Earth, the position of each point on the planet's surface can be precisely determined by simply measuring the two
angles:
longitude and
latitude.
In order to set a complete
Spatial Reference System [aka
SRS], we could have chosen to use the
Poles and the
Equator (
which after all, exists on all astronomic objects):
as the Prime Meridian of choice, or retain the, purly artificial, Greenwich Meridian, simply because it has been used for such a long time
Any SRS based on
longitude/
latitude coordinates is known as a
Geographic System.
Using a Geographic SRS surely grants you maximum precision and accuracy: but unfortunately causes undesirable side-effects:
- paper sheets (and monitor screens) being flat, they don't look like a sphere at all
- using angles makes measuring distances and areas really difficult and counter-intuitive.y/li>
For many centuries cartographers have invented several (
conventional) systems enabling to represent spherical surfaces as a flattened plane: none of which are
completely satisfactory.
All them introduce some degree of approximation and deformation.
Choosing one or the other is mostly based on the resolution of an aspect of a problem:
A good solution to correctly display a small portion of the Earth,
will be an awful solution when used to represent much bigger area
and vice versa.
We will now go through some of these solutions, explaining the
benefits and
drawbacks of each.
First, the often used,
UTM [
Universal Transverse Mercator] map projection.

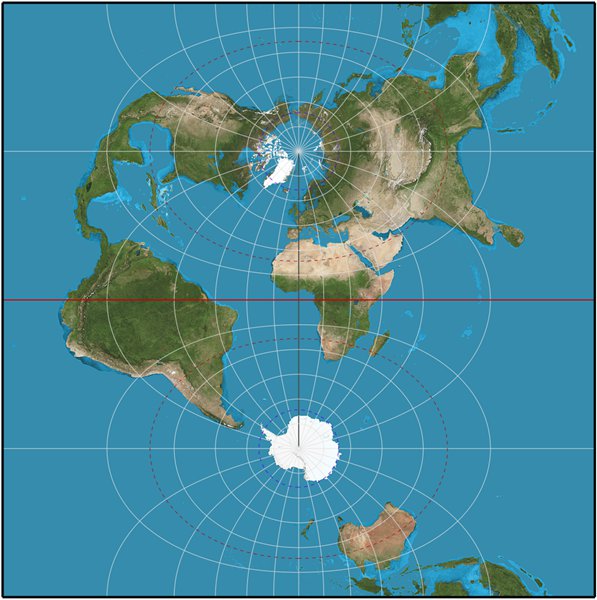
As you can see, this map projection introduces severe and
unacceptable deformations the farther you get from the
center line (between the North and South Poles)
South America at the left, India and South-East Asia on the right.
But along the
center line (Africa and Europe), you can see that UTM allows a near perfect, planar projection of excellent quality.
The area around the
center line, depending on the scale of the map, must be very narrow to remain accurate.
The wider the area gets, the stronger and more evident the deformations becomes.
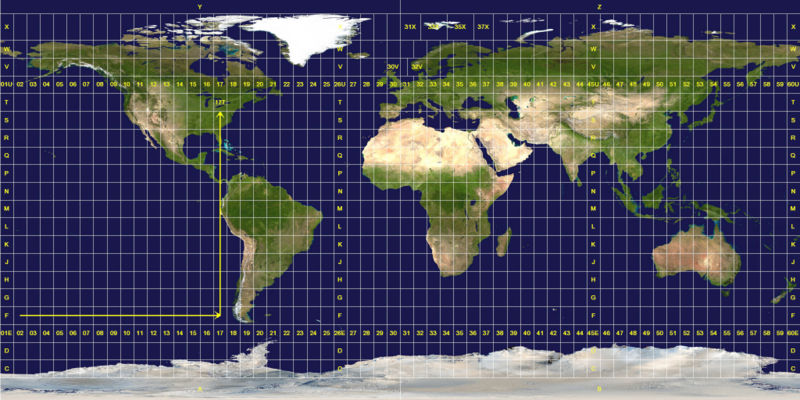
This is why UTM defines 60 standard zones, each of which covers exactly 6 longitude degrees.
Merging two adjacent zones (12 degrees) reduces the accuracy, but is still acceptable for many practical purposes.
Exceeding this limit produces low-quality results, and should be avoided.
Attempting to standardize the chaos
During the past two centuries almost every national state has introduced at least one (and very often, more than one) map projection system and related SRS : the overall result has become vary chaotic and diffecult to deal with.
Happily, an international standard has envolved which makes tha handeling map SRS easier.
The
European Petroleum Survey Group [
EPSG] maintains a huge worldwide dataset with more than 3,700 different entries.
Although many of them are now obsolete, and play only a historical role.
Others are only useful in very limited area.
This impressive collection, for which each single entry is uniquely identified by a
numeric ID and
descriptive name,
thus avoiding confusion and ambiguity.
Any Spatial DBMS requires some
SRID-value to be specified for each Geometry to correctly interpret the positions. Such SRID simply is a
Spatial Reference ID, and (
most cases) coincides with the corresponding
EPSG ID
In order to understand the SRID chaos better, here is a list of SRIDs often used in a (
small) country such as
Italy:
| 4326 |
WGS 84 |
Geographic [long-lat]; worldwide; used by GPS devices |
3003
3004 |
Monte Mario / Italy zone 1
Monte Mario / Italy zone 2 |
(Rome 1940) but still commonly used, based on the obsolete 1924 International Ellipsoid |
23032
23033 |
ED50 / UTM zone 32N
ED50 / UTM zone 33N |
European Datum 1950, also based on the 1924 International Ellipsoid, but not conforming to standard UTM zones |
32632
32633 |
WGS 84 / UTM zone 32N
WGS 84 / UTM zone 33N |
WGS84, adopting the planar UTM projection, but based upon North America
(thus, due to Continental Drift, the two opposite sides of the Atlantic Ocean become more distant, about 1 cm per year) |
25832
25833 |
ETRS89 / UTM zone 32N
ETRS89 / UTM zone 33N |
enhanced evolution of WGS84: official EU standard, based on the Tectonic Plate of Europe
(to which Italy does not belong to) |
| 3035 |
ETRS89 / LAEA Europe |
Single CRS for all Europe. Scales larger than 1:500,000: official EU standard |
And the following examples may help to understand even better:
| Roma |
4326 |
12.483900 |
41.894740 |
| 3003 |
1789036.071860 |
4644043.280244 |
| 23032 |
789036.071860 |
4644043.280244 |
| 32632 |
789022.867800 |
4643960.982152 |
| 25832 |
789022.867802 |
4643960.982036 |
| 3035 |
4527853.614995 |
2091351.235257 |
| Milano |
4326 |
9.189510 |
45.464270 |
| 3003 |
1514815.861095 |
5034638.873050 |
| 23032 |
514815.861095 |
5034638.873050 |
| 32632 |
514815.171223 |
5034544.482565 |
| 25832 |
514815.171223 |
5034544.482445 |
| 3035 |
4257519.706153 |
2483891.866830 |
As you can easily notice:
- WGS84 [4326] coordinates are expressed in decimal degrees, because this one is a Geographic System directly based on long-lat angles.
- most systems adopt coordinates expressed in meters: all these are projected aka planar systems.
- Y-values look very similar for every planar SRS: that's not surprising, because this value simply represents the distance from the Equator,
unless they adopt a false northing, as 3035 does (3210000).
- X-values are more dispersed, because different SRS's adopt different false easting origins: i.e. they place their Prime Meridian in different (conventional) point.
- Anyway, any UTM-based SRS gives very closely related values, simply because all them share the same UTM zone 32 definition.
- The (small) differences you can notice about different UTM-based SRSes can be easily explained: UTM zone 32 is always the same, but the underlying ellipsoid changes each time.
Getting a precise measure for an ellipsoid's axes isn't an easy task: and obviously over time several increasingly better and more accurate estimates have been progressively adopted.
| 4326 |
4.857422 |
| 3003 |
477243.796305 |
| 23032 |
477243.796305 |
| 32632 |
477226.708868 |
| 25832 |
477226.708866 |
| Great Circle |
477109.583358 |
| Geodesic |
477245.299993 |
| 3035 |
476622.040725 |
And now we can examine how using different SRS's affects distances:
- Using WGS84 [4326] geographic, long-lat coordinates we'll actually get a measure corresponding to an angle expressed in decimal degrees. [not so useful, really ...]
- any other SRS will return a distance measure expressed in meters: as you see, the results aren't exactly the same.
- Great Circle distances are calculated assuming that the Earth is exactly a sphere: and this one obviously is the worst estimate we can get.
- on the otherhand Geodesic distances are directly calculated on the reference Ellipsoid.
You may have also noted, that the worst distance (> 600 meters) returned was from 3035 (ETRS89 / LAEA Europe), which is only intended to be used for large areas.
The deformations seen above in the World-Image make itself here, as
numbers, noticeable, since the distance being measured is far from the center of the projected area.
That is why the
remarks about 'ETRS89 / LAEA Europe' should be carefully read:
Single CRS for all Europe. Used for statistical mapping at all scales and other purposes where true area representation is required.
Use ETRS89 / LCC (code 3034) for conformal mapping at 1:500,000 scale or smaller or ETRS89 / UTM (codes 25828-37 or 3040-49) for conformal mapping at scales larger than 1:500,000.
Conclusion::
Thou shall not have exact measures
But this isn't at all surprising since in physical and natural sciences: any measured value is always affected by errors and approximations.
Also any calculated value will be effected by rounding and truncation artifacts.
Since an absolutely exact result simply doesn't exist in the real world: be aware you will get nothing more than, a more or less an approximated, value.
The goal should be to know how to properly reduce such approximations in the best possible way.
Specialized conditions, bring about specialize solutions.
For a country like Italy, where the area
from the Alps, down along the Apennines, including the western coastline over to the western island of Sardinia
- special conditions exist, as the image right shows, that other contries don't have.
For this reason, the "Istituto Geografico Militare" (IGM) has, since 1995, started adapting high-precision SRSes specifically intended to address these problems
| 3064 |
IGM95 / UTM zone 32N |
Scientific study |
| 3065 |
IGM95 / UTM zone 33N |
Scientific study |
| 4670 |
IGM95 |
Horizontal component of 3D system |
Being based on the Italian Plate (
Alpine orogeny)these SRSes are more suited to Italian needs,
as opposed the others that are based on the Tectonic Plate of Europe (not to mention that of North America), and are expected to fully preserve their precision over the next few centuries..

Summa summarum:
Great care must be taken to correctly chose which projection to use:
based on what the projection was designed for and your needs
How
spatialite_gui will look, after submitting a standard SQL-Query:
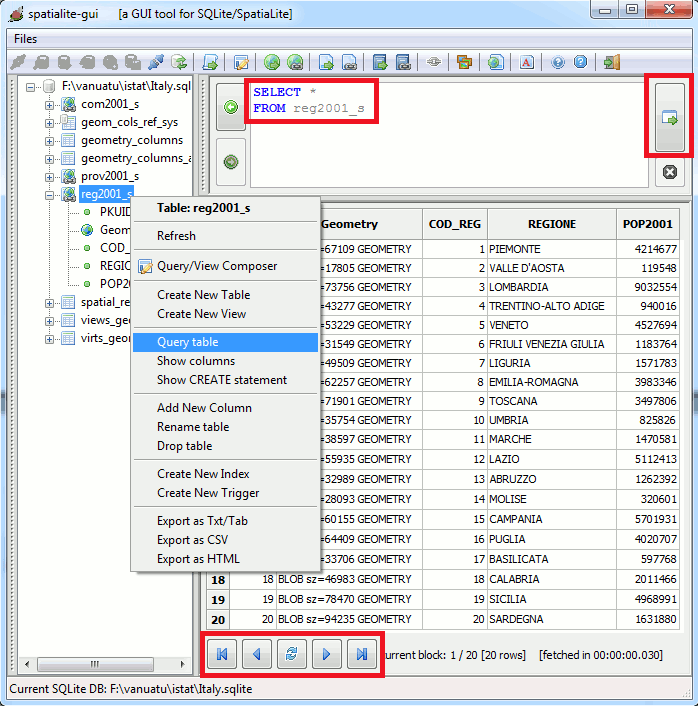
You can follow two different approaches in order to query a DB table:
- you can simply use the Query Table menu item.
- this the quickest and easiest way and completely user friendly.
- you simply have to click the mouse's right button over the required table, for the context menu to be shown.
- then you can simply use the lowermost buttons in order to scroll the result-set to the: top/prev/next/end at as you need it.
- this approach is rather mechanical, and doesn't allow you to exploit the powerful capabilities of SQL, by refining the result-set as you need it.
- Note: the records of the result-set can be changed, since a ROWID exists
- alternatively you can hand-write any arbitrary SQL statement into the uppermost pane, then pressing the Execute button.
- this one is the hardest way: you are responsible for what you are doing (or even misdoing ...)
- but this way you can take full profit of the powerful capabilities of SQL, by refining the result-set as you need it.
- Note: the records of the result-set cannot be changed, since no ROWID exists
In both cases, only 500 records of the
result-set will, at first, be returned.
- Pressing the next or previous button will then retrieve the next or previous 500 records
- Pressing the reset button (in the middle) will retrieve the same 500 records again
- Pressing the first or last button will then retrieve the first or last 500 records
TODO: Add SQL-Filter Dialog
Add description with spatialite_gui image.
|
 |
Add SQL-Filter Dialog
This dialog insures that the result-set of filtered SQL-Statements, that mostly does not have a ROWID,
can never the less be used with UPDATE/DELETE statements.
This makes it possible to change/edit the result-set in the Data-View.
Note: any change in the syntax of created SQL, will invalidate the edit-mode and the result-set will be come read-only.
|
How
spatialite_gui will look, after opening the
BLOB explorer:
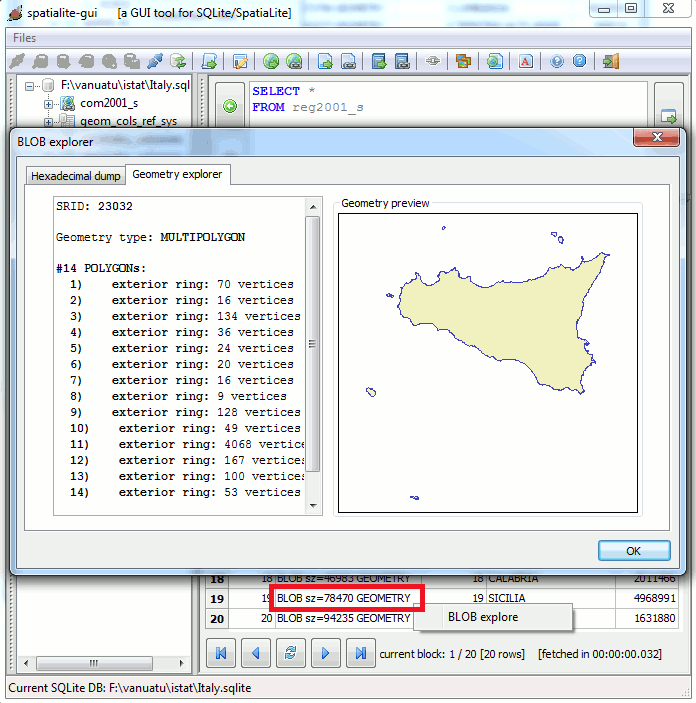
BLOB GEOMETRY: will show the size of the stored binary-data
sz=nnn
Using the
BLOB explorer function, by simply clicking the mouse's right button over the corresponding value, will give you a much richer preview of any Geometry.
A quick overview of
cities1000:
SELECT
"The 'cities1000' table contains cities of of the world with a population ≥ 1000 ("||
(SELECT count(id_rowid) FROM cities1000)||" records),"||char(10)||" "||
(SELECT count(id_rowid) FROM cities1000 WHERE (country_code = 'IT'))||
" of which are in Italy (country_code = 'IT')" AS message;
The 'cities1000' table contains cities of of the world with a population ≥ 1000 (128743 records),
9900 of which are in Italy (country_code = 'IT')
-
during the import of the data, we set default values invalid/non-set data (elevation = 0)
- CASTING for numeric data was also done to insure that mubers are correctly interpreted
- CASTING for elevation to DOUBLE (supporting mm) which is the most common use for dem-data
- the table was filled with sorting order of: country_code, admin1_code, name
You can test how a
free-hand SQL works using this SQL statement:
SELECT
name,
country_code,
admin1_code,
admin2_code,
admin3_code,
population,
elevation,
longitude,
latitude,
geom_wgs84
FROM cities1000
WHERE
( -- will check the 128556 records that fulfills this condition, returning 23 records
(elevation < 0)
)
ORDER BY elevation DESC;
simply
copy the SQL statement, then
paste it into the query panel, and finally press the
Execute button to create a
result-set.
With
spatialite_gui returning a
result-set which will look something like this:
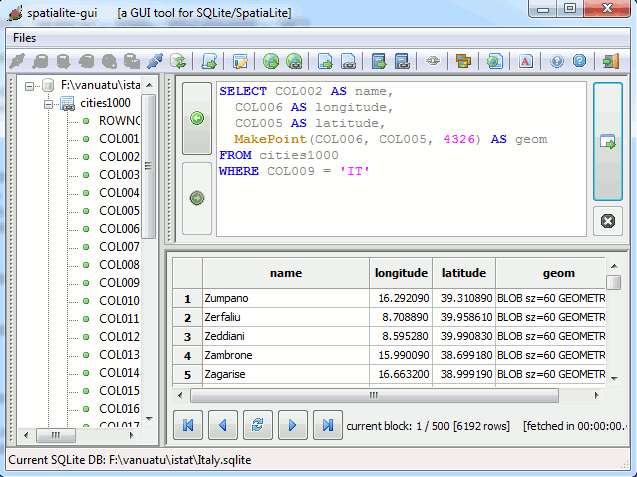
The Sql-Query will list all cities, where the
elevation is < 0,
sorted with the
highest value first.
- will return 23 records, the highest being -1.0 meters, the lowest -60.0 meters
'(elevation < 0)' is called a
filter (or
WHERE) condition.
A
WHERE Statement can contain more that one
filter condition.
The
first condition will
always read/query all of the records (in our case 128556) of the TABLE.
- When more than 1 filter condition is being used
- the following conditions will only be performed on those records that fulfill the previous conditions.
Therefore the
order of the conditions is important.
We will now add a new
filter condition:
(country_code = 'IT') (cities in Italy)
-
Question: what is easier to do?
- Check if the 9900 cities in Italy have an elevation < 0 ?
or
- Check if the 23 cities that have an elevation < 0 are in Italy?
I would chose the second option, adaption the
WHERE Statement in this way
- since both conditions must be fulfilled, we will add an 'AND' after the first condition
WHERE
( -- will check the 128556 records of the table (first condition)
(elevation < 0) AND
-- will check the 23 records that have an elevation < 0
(country_code = 'IT')
)
The result: 1 record, retrieved in 00:00:00.098 ms [as opposedd to 00:00:00.104]
Scardovari IT 20 RO 029039 1434 -1.000000 12.454620 44.897650
Not satisfied with that, but also want the cities in Iran?
- since one or the other of the second condition must be fulfilled, inclose them inside brackets add an 'OR' between them
WHERE
( -- will check the 128556 records of the table (first condition)
(elevation < 0) AND
-- will check the 23 records that have an elevation < 0
((country_code = 'IT') OR (country_code = 'IR'))
)
The result: 2 records.
Scardovari IT 20 RO 029039 1434 -1.000000 12.454620 44.897650
Ziabar (Gaskar) IR 08 4500 -7.000000 49.245900 37.426100
Still not satisfied ?? Because there is too much to type ??
- use a list of conditions for 1 column with 'IN ('IT','IR')'
WHERE
( -- will check the 128556 records of the table (first condition)
(elevation < 0) AND
-- will check the 23 records that have an elevation < 0
(country_code IN ('IT','IR'))
)
with the same result.
With that, you have enough to start experiment with.
A proper understanding of the WHERE statement is very important, so familiarizing yourself by quering data for an area of your interest, where you have a good idea of what results should be , would be a good idea.
The following SQL queries are so elementary that you can directly verify the results yourself.
Simply follow any example executing the corresponding SQL statement (using
copy&paste).
This one really is the
pons asinorum of SQL:
all columns for each row of the selected table will be dumped following a random order
SELECT
*
FROM com2011_s;
This is what you use when you have
no idea what the table contains.
There is no need to retrieve every column:
You can explicitly choose:
- which columns have to be included in the result-set
- establishing the relative column-order within the result set
- (you can also sort and filter the results, more about that later)
SELECT
pop_2011, comune
FROM com2011_s;
Here, the first column will be 'pop_2011', the second then 'comune' (in the original table it is the other way around)
You can also re-name each column, so that the shown column-name (for the user) is more explanitory.
SELECT
Pro_cOm AS code, COMUNE AS name,
pop_2011 AS "population (2011)"
FROM com2011_s;
This sample shows two
important aspects to
must be heeded:
- SQL names are case-insensitive: COMUNE. and comune. refers the same column.
- SQL names cannot contain forbidden characters (such as spaces, brackets, colons, hyphens and so on).
And they cannot correspond to any reserved keyword (i.e. you cannot define a column named e.g. SELECT or FROM., because they shadow SQL commands)
- 'Cheating' is, of course, possible by explicitly setting a mask for any forbidden name, thus becoming a permissable name.
In order to apply such masking, you simply must enclose the full name within a pair of double quotes.
- you can, obviously, double quote every SQL name: this is completely harmless, but don't ask for extra time for doing so ....
- in the (extremely rare, but not impossible) case that your, corrected, forbidden name already contains one or more double quote characters, then you must insert an extra double quote for each one of them.
e.g.: A"Bc"D has to be correctly masked as: "A""Bc""D"
SQL allows you to order rows into the result-set in almost any form that you need.
Here the Communities will be sorted Alphabetically:
SELECT
pro_com, comune, pop_2011
FROM com2011_s
ORDER BY comune;
Here the result will first be sorted by the Region id (numeric, descending) and then by the Community names (alphabetically, ascending) :
SELECT
cod_reg, pro_com, comune, pop_2011
FROM com2011_s
ORDER BY cod_reg DESC, comune ASC;
(Whether this is sensible or not, is is a completely different question)
You can order as
ASC.ending or as
DESC.ending order, as needed.
The ASC. qualifier is usually omitted, since it is the default ordering
- Ascending order means A-Z for text values: and from lesser to greater for numeric values.
- Descending order means Z-A for text values: and from greater to lesser for numeric values.
SELECT
pro_com, comune, pop_2011
FROM com2011_s
ORDER BY pop_2011 DESC;
Using the
WHERE. clause you can restrict the range:
only the rows satisfying the WHERE. clause condition will be placed into the result-set.
In this case, the list of Provinces belonging to Tuscany Region will be extracted.
SELECT
cod_pro, provincia, sigla
FROM prov2011_s
WHERE
(cod_reg = 9);
Same as above: this time the list of Communities belonging to the Florence Province will be extracted.
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
(cod_pro = 48);
With a
WHERE. clause: you can define as many conditions as are needed
Here a list of larger Communities (population > 50,000), within the Tuscany Region, will be extracted.
And the result-set will be ordered the
largest population being shown first ['
DESC'].
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
(
(cod_reg = 9) AND
(pop_2011 > 50000)
)
ORDER BY pop_2011 DESC;
You can obviously use text strings as comparison values:
in
pure SQL any text string has to be enclosed within
single quotes.
SQLite is smart enough to recognize double quoted text strings as well, but I strongly discourage you from adopting such a bad style !!!
Furthermore: string values comparisons for SQLite are always
case-sensitive.
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
( -- search independent of upper/lower case
(Upper(comune) = 'ROMA')
);
When a text string contains an
apostrophe, you
must apply
masking.
An extra
single quote is required to mask every apostrophe within a text string:
e.g.: REGGIO NELL'EMILIA has to be correctly masked as: 'REGGIO NELL''EMILIA'
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
( -- search independent of upper/lower case
(Upper(comune) = 'L''AQUILA')
);
You can use the
approximate evaluation operator
LIKE to make
case-insensitive.text comparisons:
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
( -- insensitive to upper/lower case
(comune LIKE 'roma')
);
And you can use the operator
LIKE so to apply partial text comparison, using
% or '
_' as a wild-card:
Beware: do not use the dos/linix wild-cards '*' and '?'
This query will extract any Local Council containing the sub-string
'maria' within its name.
- '%maria%': everything before and after will be ignored
- '%maria': everything before will be ignored and must end with 'maria'
- 'maria%': must start with 'maria', everything after will be ignored
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
( -- insensitive to upper/lower case
(comune LIKE '%maria%')
);
26 records when using
'%maria%'
32 records when using
'%m_ria%' ('Lo
mb
riasco' being one of them)
'_' being used as a wild-card for a single letter
Sometimes it may be useful to use a
list of values as a filter:
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
( -- search independent of upper/lower case
(Upper(comune) IN ('ROMA', 'MILANO', 'NAPOLI'))
);
Note: Without the use of Upper, no results would be returned.
Another, not often used but sometimes useful, to
set a range of values as a filter:
SELECT
pro_com, comune, pop_2011
FROM com2011_s
WHERE
( -- Numbers from/to (inclusive)
(pop_2011 BETWEEN 1990 AND 2010)
);
First result should be: 3135 San Pietro Mosezzo 1996.000000
Using SQL you can set any kind of complex
WHERE. clause: there are no imposed limits (other that it might become
unreadable for others, if not properly formatted/documented).
This is a really fantastic a feature, offering infinite scenarios.
Here a short explanation of what the next query will (should) do:
- include any County in Central Italy (Regions: Tuscany, Umbria, Marche and Lazio)
- excluding the Livorno and Pisa Provinces
- then filter the Provinces by population:
- including the ones within the range 300,000 to 500,000 (inclusive)
- but also including the ones exceeding a population of 750,000
using a subquery based on the secondary-key of the province, since the table does not contain a population field.
SELECT
provincia, sigla, pop_2011
FROM prov2011_s
WHERE
( -- Regions: Tuscany, Umbria, Marche and Lazio
(cod_reg IN (9, 10, 11, 12)) AND
-- but excluding the Livorno and Pisa Provinces
(sigla NOT IN ('LI', 'PI')) AND
( -- Numbers from/to (inclusive)
(pop_2011 BETWEEN 300000 AND 500000) OR
-- but also when
(pop_2011 > 750000)
)
);
Warning: in SQL the logical operator
OR has a lower priority than
AND.
Changing the placement of the OR-clause within brackets, will produces very different results, does it not ?
Another, sometimes useful,
SELECT clause is: using
LIMIT you can set the maximum number of rows to be extracted into the result-set
(
very often you aren't actually interested in reading a very large table at all: often a preview is enough).
SELECT
*
FROM com2011_s
-- show only 10 rows
LIMIT 10;
And that's not all:
SQL allows you set the amount of rows to skip, togeather with a limited row-set, by using OFFSET. combined with LIMIT.
SELECT
*
FROM com2011_s
-- show only 10 rows
LIMIT 10
-- starting after row 1000
OFFSET 1000;
Learning SQL is not really that difficult.
There are very few keywords and the language syntax is notably regular and predictable, and query statements are designed to resemble plain English (as much as possible ...).
Although 'trial and error' is unavoidable, writing (simple) SQL query statements by yourself, checking the expected, known results, is the best way to start.
We've seen since now how SQL allows to retrieve single values on a row-per-row basis.
Another approach is also possible, one allowing to compute
total values for the whole table, or for a group(s) of selected rows.
This implies using some special functions, known as
aggregate functions.
SELECT
-- return the calculated amount of rows in 'com2011_s' and call it 'com2011_count'
Count(pop_2011) AS com2011_count,
-- return the lowest found value of 'pop_2011' in 'com2011_s' and call it 'pop_2011_min'
Min(pop_2011) AS pop_2011_min,
-- return the highst found value of 'pop_2011' in 'com2011_s' and call it 'pop_2011_max'
Max(pop_2011) AS pop_2011_max,
-- return the calculated average value of 'pop_2011' in 'com2011_s' and call it 'pop_2011_avg'
Avg(pop_2011) AS pop_2011_avg,
-- return the calculated total value of 'pop_2011' in 'com2011_s' and call it 'pop_2011_sum'
Sum(pop_2011) AS pop_2011_sum
FROM com2011_s;
This query will return a single row, representing something like a summary for the whole table:
- the Min(). function will return the minimum value found in the given column
- the Max(). function will return the maximum value found in the given column
- the Avg(). function will return the average value for the given column
- the Sum(). function will return the total value for the given column
- the Count(). function will return the number of rows (entities) found
You can use the
GROUP BY clause in order to establish a more finely grained aggregation/selection by sub-groups
- Thus performing calculations on all rows that contain that particular value
- For each unique value found
This query will return distinct results for each County:
- for each row containing the value of the County id
- bur returning only 1 row with the result
SELECT
-- Calculate the Min/Max,Avg/sum and amount based on this value
cod_pro,
-- subquery is needed since 'com2011_s' does not have a field containing the county-name, only the id
(SELECT provincia FROM prov2011_s WHERE (com2011_s.cod_pro=prov2011_s.cod_pro)) AS province_name,
Count(pop_2011) AS com2011_count,
Min(pop_2011) AS pop_2011_min,
Max(pop_2011) AS pop_2011_max,
Avg(pop_2011) AS pop_2011_avg,
Sum(pop_2011) AS pop_2011_sum
FROM com2011_s
-- Group the result by this value before any calcuation is done
GROUP BY cod_pro;
110 records, first listing the Province id and name, then the calculated results.
And you can obviously get results for each Region simply changing the
GROUP BY criteria:
SELECT
-- Calculate the Min/Max,Avg/sum and amount based on this value
cod_reg,
-- subquery is needed since 'com2011_s' does not have a field containing the region-name, only the id
(SELECT regione FROM reg2011_s WHERE (com2011_s.cod_reg=reg2011_s.cod_reg)) AS region_name,
Count(pop_2011) AS com2011_count,
Min(pop_2011) AS pop_2011_min,
Max(pop_2011) AS pop_2011_max,
Avg(pop_2011) AS pop_2011_avg,
Sum(pop_2011) AS pop_2011_sum
FROM com2011_s
-- Group the result by this value before any calcuation is done
GROUP BY cod_reg;
20 records, first listing the Region id and name, then the calculated results.
One result is:
9 Toscana 287 328.000000 358079.000000 12795.128920 3672202.000000
- 9 = Region id
- Toscana = region-name
- 287 records for the Toscana were found (out of 8081 records inside the table 'com2011_s')
- 328 = the lowest population of a town/city in the Toscana
- 358079 = the highest population of a town/city in theToscana
- 112795.128920 = the average population of a town/city in theToscana
- 3672202 = the total population of all towns/citys in theToscana
Summa summarum: The Toscana has a population of 3672202 in 2011.
There is another different way to aggregate rows: i.e. using the
DISTINCT. clause:
SELECT
DISTINCT cod_reg, cod_pro
FROM com2011_s
ORDER BY cod_reg, cod_pro;
However: the result is
not the same as when using the
GROUP BY clause:
- DISTINCT. removes non-unique rows and therefore cannot perform any calulation on those, removed, rows.
-
GROUP BY is absolutely required when you have to properly control an aggregation result (i.e. for the calculations of values per 'DISTINCT' result).
- will sort all the records by the given value
- will loop through all the records
when the value changes: the caluculated result will be stored as a result record
when the loop is completed, the stored results will be returned.




After all, the main rule on which nature is based on is: I ask you: What can be more logical than that?
But no, while I am (yet again) busy cleaning up the resources THAT THEY demanded, and of course forgot to remove themselves (let the computer do, as always) ....
And of course, then there are those, ignoring my nicely organized placement of the data - THAT THEY (as allways) absolutly need NOW ('Why is the computer so SLOW?', they ask)
- sloping it over with other things that they have created, because it doesn't fit in the space THAT THEY requested ....
Really, it is times like these when I just turn myself off and let them do it by themself.
But, of course, within a few seconds, there THEY are, proding me back to work, because of course, THEY can't do by themselvs. And whoes to blame? The 'stupid computer' of course (as always)!
One does wonder how these biological things ... (mutter ... mutter ... mutter) ....
in compliance with the Network Enforcement Act
the viewpoint of the computer had be cleaned up and shortend.